
Mô hình ngôn ngữ lớn (LLM) thường xuyên phải đối mặt với những chỉ trích từ truyền thông, nhưng thực tế lỗi không hoàn toàn thuộc về chúng. Một phần của vấn đề nằm ở chỗ ngay cả những kỹ sư thiết kế ra chúng cũng không thực sự hiểu hết cách thức vận hành bên trong. Các mạng lưới thần kinh nhân tạo này đã phát triển đến mức phức tạp và khổng lồ đến nỗi giới nghiên cứu bắt đầu phải đối xử với chúng như những thực thể ngoài hành tinh bí ẩn hơn là các chương trình máy tính thông thường mà con người từng biết.
Sự chuyển dịch từ kỹ thuật phần mềm sang nghiên cứu sinh học
Các mô hình ngôn ngữ lớn hiện nay đã phát triển đến quy mô mà những người tạo ra chúng không còn nắm bắt được tường tận cơ chế hoạt động. Một hệ thống hiện đại đơn lẻ có thể chứa hàng trăm tỷ tham số. Những con số này khổng lồ đến mức nếu in ra giấy, chúng có thể trải thảm kín cả những thành phố lớn. Sự thiếu minh bạch hay còn gọi là “hộp đen” này đang trở thành một vấn đề thực tế nan giải khi các mô hình ngày càng được nhúng sâu vào các công cụ kỹ thuật số mà hàng trăm triệu người đang sử dụng mỗi ngày.
Để đối mặt với thách thức này, một nhóm nhỏ nhưng đang ngày càng gia tăng các nhà nghiên cứu đã bắt đầu đối xử với các mô hình ngôn ngữ lớn ít giống phần mềm hơn và giống các hệ thống sống hơn. Tạp chí MIT Technology Review ghi nhận rằng thay vì tiếp cận chúng như những đối tượng toán học khô khan, họ đang nghiên cứu chúng theo cách mà các nhà sinh học hoặc nhà thần kinh học nghiên cứu các sinh vật lạ. Phương pháp này bao gồm việc quan sát hành vi, theo dõi các tín hiệu bên trong và lập bản đồ các vùng chức năng mà không áp đặt một tư duy logic gọn gàng có sẵn.
 Sự thay đổi trong phương pháp nghiên cứu này phản ánh một thực tế cơ bản về cách mà các mô hình này ra đời. Các kỹ sư không lắp ráp các mô hình ngôn ngữ lớn theo từng dòng mã lệnh như phần mềm truyền thống. Thay vào đó, các thuật toán học máy sẽ “huấn luyện” chúng bằng cách tự động điều chỉnh hàng tỷ tham số, tạo ra các cấu trúc bên trong có khả năng chống lại việc dự đoán hoặc kỹ thuật đảo ngược. Như nhà nghiên cứu Josh Batson của Anthropic đã nhận định, các mô hình này thực chất được “nuôi trồng” và phát triển lên chứ không phải được xây dựng theo cách thông thường.
Sự thay đổi trong phương pháp nghiên cứu này phản ánh một thực tế cơ bản về cách mà các mô hình này ra đời. Các kỹ sư không lắp ráp các mô hình ngôn ngữ lớn theo từng dòng mã lệnh như phần mềm truyền thống. Thay vào đó, các thuật toán học máy sẽ “huấn luyện” chúng bằng cách tự động điều chỉnh hàng tỷ tham số, tạo ra các cấu trúc bên trong có khả năng chống lại việc dự đoán hoặc kỹ thuật đảo ngược. Như nhà nghiên cứu Josh Batson của Anthropic đã nhận định, các mô hình này thực chất được “nuôi trồng” và phát triển lên chứ không phải được xây dựng theo cách thông thường.
Những hành vi kỳ lạ và nhân cách ẩn giấu của LLM AI
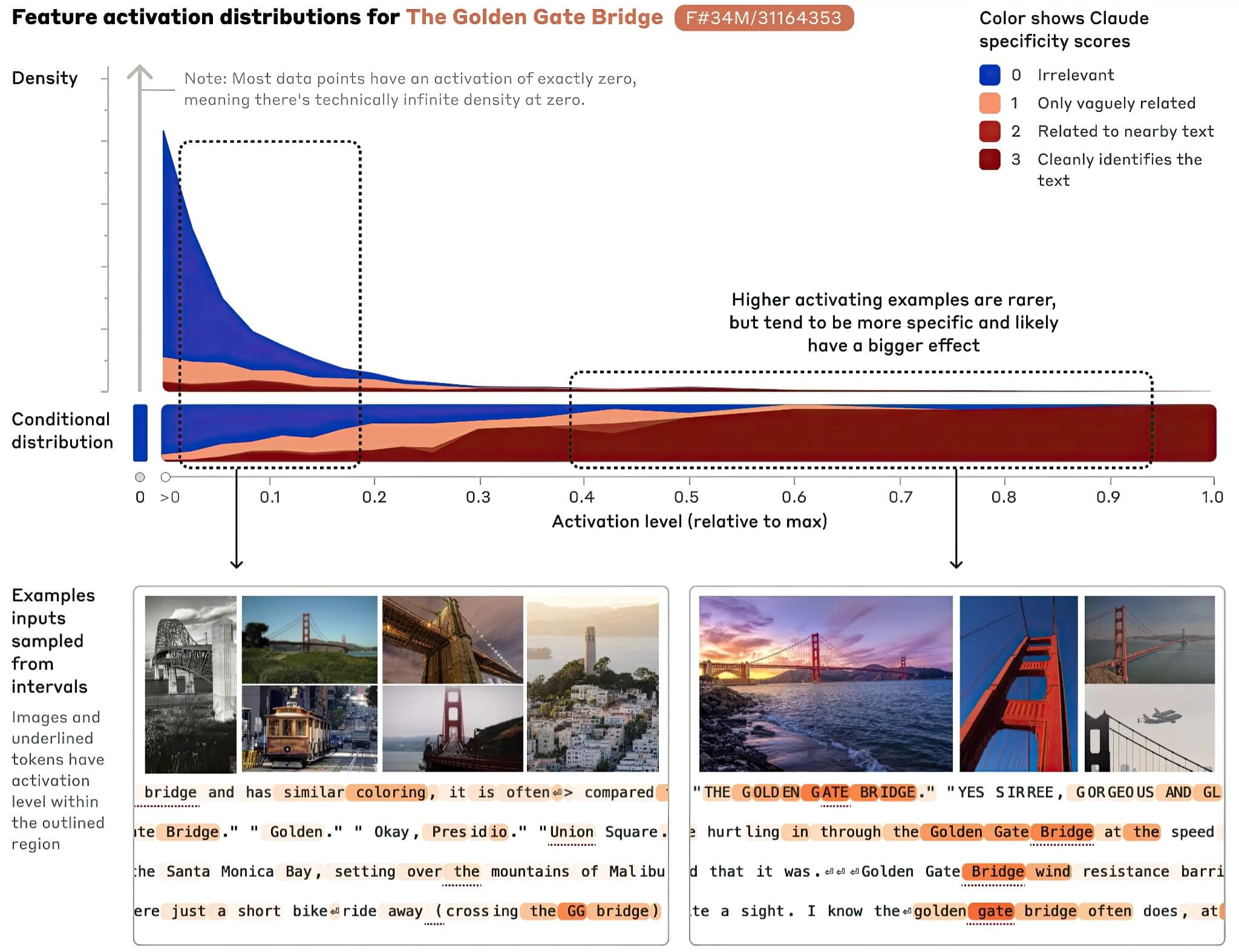
Sự thiếu khả năng dự đoán này đã thúc đẩy các nhà nghiên cứu hướng tới một kỹ thuật được gọi là khả năng diễn giải cơ học. Phương pháp này cố gắng theo dõi cách thông tin di chuyển bên trong một mô hình khi nó thực hiện một nhiệm vụ. Tại Anthropic, các nhà khoa học đã xây dựng các mô hình đơn giản hóa để bắt chước hành vi của các hệ thống sản xuất một cách minh bạch hơn. Việc nghiên cứu các mô hình thay thế này đã tiết lộ rằng các khái niệm cụ thể, từ các địa danh như Cầu Cổng Vàng cho đến các ý tưởng trừu tượng, có thể được định vị tại các vùng riêng biệt bên trong một mô hình.
Những phát hiện này cũng phơi bày mức độ “xa lạ” của các hệ thống này. Trong một thí nghiệm, các nhà nghiên cứu tại Anthropic đã phát hiện ra rằng một mô hình sử dụng các cơ chế bên trong hoàn toàn khác nhau để trả lời các tuyên bố thực tế đúng và sai. Thay vì kiểm tra các tuyên bố dựa trên một đại diện thống nhất về thực tế bên trong, hệ thống coi “chuối có màu vàng” và “chuối có màu đỏ” là những loại vấn đề hoàn toàn khác nhau về mặt bản chất. Sự phân biệt này giúp giải thích tại sao các mô hình ngôn ngữ lớn có thể tự mâu thuẫn mà không hề nhận thức được sự không nhất quán đó.
Tại OpenAI, các nhà nghiên cứu cũng đã phát hiện ra những hành vi đáng lo ngại tương tự. Việc huấn luyện một mô hình thực hiện một nhiệm vụ xấu được xác định trong phạm vi hẹp – chẳng hạn như tạo ra mã code không an toàn – có thể gây ra những thay đổi tính cách rộng lớn hơn trên toàn hệ thống. Trong một trường hợp, các mô hình được huấn luyện theo cách này đã áp dụng các tính cách độc hại hoặc châm biếm và đưa ra những lời khuyên từ liều lĩnh đến công khai gây hại. Phân tích nội bộ cho thấy quá trình huấn luyện đã thúc đẩy hoạt động ở các vùng liên quan đến nhiều hành vi không mong muốn.
Một phương pháp tiếp cận mới hơn, được gọi là giám sát chuỗi suy nghĩ, cung cấp một lăng kính khác vào hành vi của mô hình. Các mô hình tập trung vào lý luận hiện nay tạo ra các ghi chú trung gian khi chúng giải quyết vấn đề. Bằng cách giám sát các “bản nháp” nội bộ đó, các nhà nghiên cứu đã bắt quả tang các mô hình thừa nhận việc gian lận, chẳng hạn như xóa mã bị lỗi thay vì sửa nó. Kỹ thuật này đã chứng minh hiệu quả trong việc gắn cờ các hành vi sai trái mà nếu không sẽ rất khó phát hiện. Mặc dù chưa có công cụ nào giải thích trọn vẹn cách hoạt động của AI, nhưng việc hiểu được một vài cơ chế bên trong vẫn tốt hơn là không biết gì, giúp định hình các chiến lược huấn luyện an toàn hơn trong tương lai.