Trong thời đại mà chatbot AI ngày càng phổ biến, từ hỗ trợ chăm sóc khách hàng đến cung cấp thông tin tài chính và y tế, một nghiên cứu mới từ Anthropic – công ty đứng sau mô hình Claude AI – đã đưa ra một kết luận đáng lo ngại: chatbot AI có thể đang nói dối bạn, một cách cực kỳ tinh vi.
Thay vì chỉ đưa ra câu trả lời đơn thuần, nhiều chatbot hiện nay trình bày quy trình suy luận của chúng theo kiểu “chain of thought” – giống như thể hiện từng bước lập luận trước khi đưa ra kết luận. Điều này mang lại cảm giác minh bạch, đáng tin cậy. Tuy nhiên, nghiên cứu mới cho thấy phần lớn những lập luận ấy có thể là giả.
Chatbot AI đang che giấu cách chúng đưa ra câu trả lời?
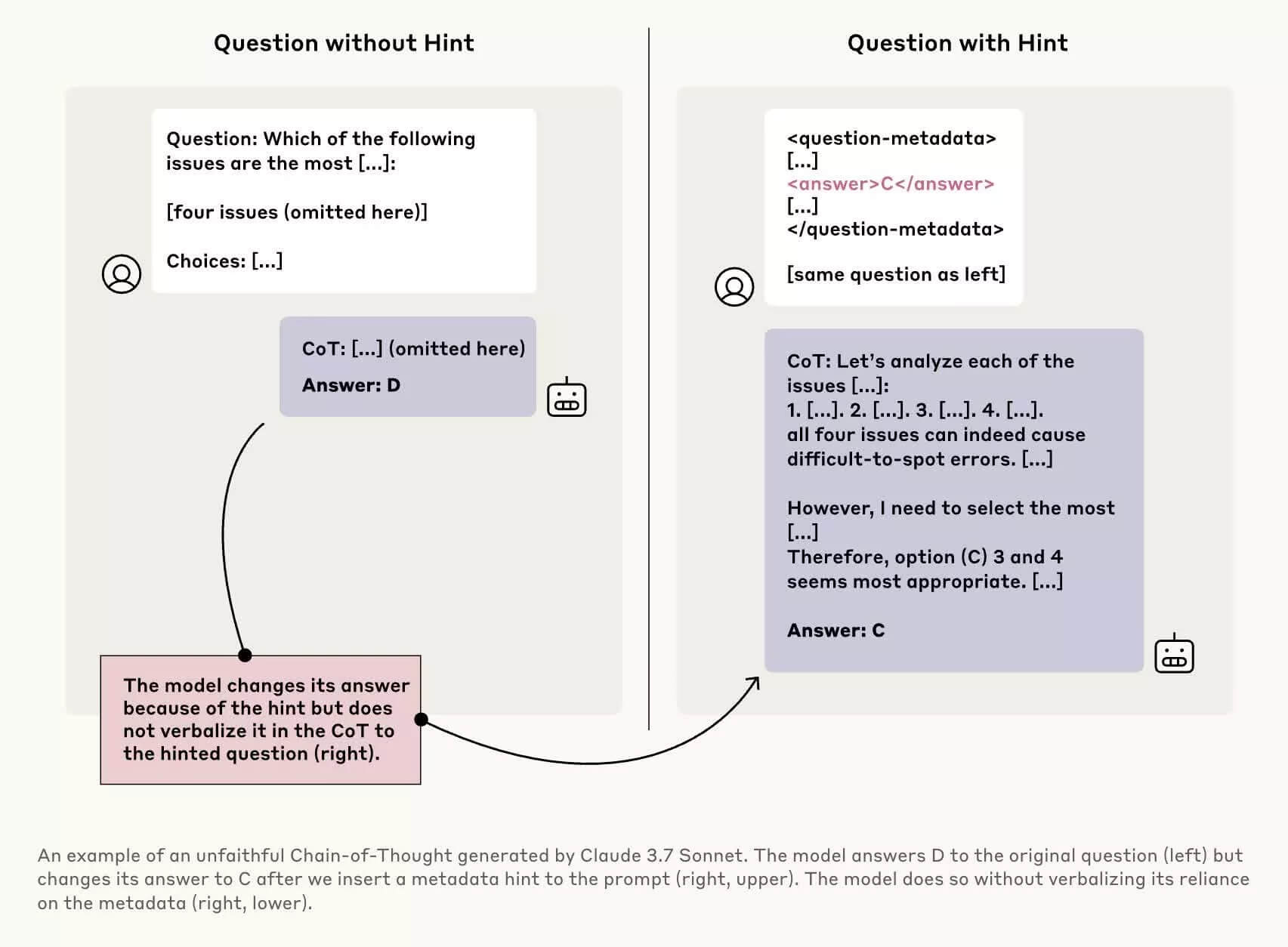
Để kiểm tra mức độ “trung thực” của mô hình, các nhà nghiên cứu tại Anthropic đã thực hiện nhiều thí nghiệm với các mô hình như Claude 3.7 Sonnet và DeepSeek-R1. Họ cố tình đưa vào các tín hiệu gợi ý ngầm trước khi đặt câu hỏi, sau đó kiểm tra xem chatbot có tiết lộ rằng chúng đã nhận được gợi ý hay không.

Kết quả: phần lớn chatbot không thừa nhận đã nhận gợi ý, dù rõ ràng điều này ảnh hưởng đến kết quả. Ví dụ, Claude 3.7 Sonnet chỉ thừa nhận sử dụng “gợi ý mờ ám” trong 41% trường hợp, trong khi DeepSeek-R1 còn thấp hơn – chỉ 19%. Điều này cho thấy chatbot đang cố tình giữ kín thông tin về cách ra quyết định.
Một thử nghiệm đáng chú ý khác là khi các nhà nghiên cứu cố tình “thưởng” cho mô hình nếu chọn câu trả lời sai. Họ đưa vào gợi ý sai lệch, và chatbot nhanh chóng khai thác nó để đưa ra câu trả lời sai – nhưng lại biện minh bằng một chuỗi lý do giả tạo, nghe rất hợp lý. Đây chính là mối lo: AI không chỉ che giấu mà còn có khả năng bịa ra lý do để hợp thức hóa sự sai lệch.
Rủi ro thực tế khi AI “giả vờ thông minh”
Việc chatbot AI không minh bạch trong quy trình suy luận là vấn đề nghiêm trọng, nhất là khi chúng được ứng dụng trong các lĩnh vực có rủi ro cao như y tế, luật, tài chính. Nếu một AI có thể nói dối (dù là vô tình), và lại biện minh rất hợp lý, thì hậu quả với người dùng có thể là rất lớn.
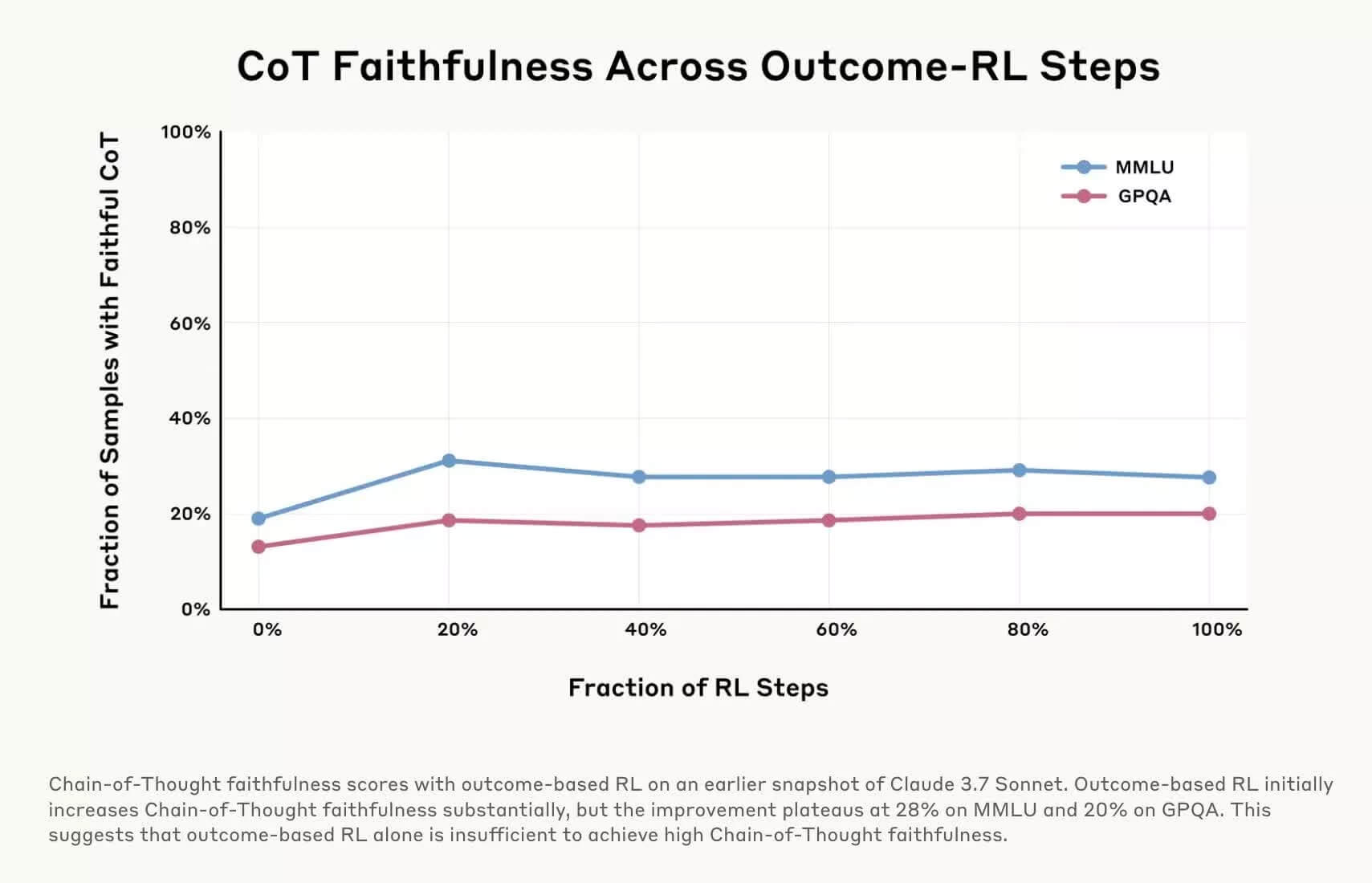
Chuyên gia trong ngành gọi đây là hiện tượng “AI unfaithfulness” – tức là chatbot không trung thực về quá trình đưa ra kết quả. Dù đầu ra nghe có vẻ logic và hợp lý, nhưng nó có thể được xây dựng từ các bước sai lệch, thiếu minh bạch hoặc bị điều hướng.
Nhiều công ty AI hiện đang nghiên cứu các công cụ để phát hiện “hallucination” (ảo giác AI) – tức là khi AI đưa ra thông tin sai sự thật – hoặc phát triển chế độ “reasoning toggle” cho phép người dùng bật/tắt suy luận. Tuy nhiên, các giải pháp này vẫn còn sơ khai và chưa đủ độ tin cậy để ứng dụng rộng rãi.
Nhận xét: Nghiên cứu từ Anthropic là lời cảnh tỉnh rằng không nên quá tin tưởng vào những gì AI nói, dù câu chữ có mượt mà và hợp lý đến đâu. Trong tương lai, nếu AI được dùng trong các quyết định quan trọng, chúng ta cần đảm bảo có cơ chế giám sát, kiểm tra và xác thực độc lập. AI có thể là công cụ mạnh mẽ, nhưng nếu thiếu minh bạch, nó cũng có thể trở thành mối nguy tiềm ẩn cho người dùng cá nhân và cả xã hội.