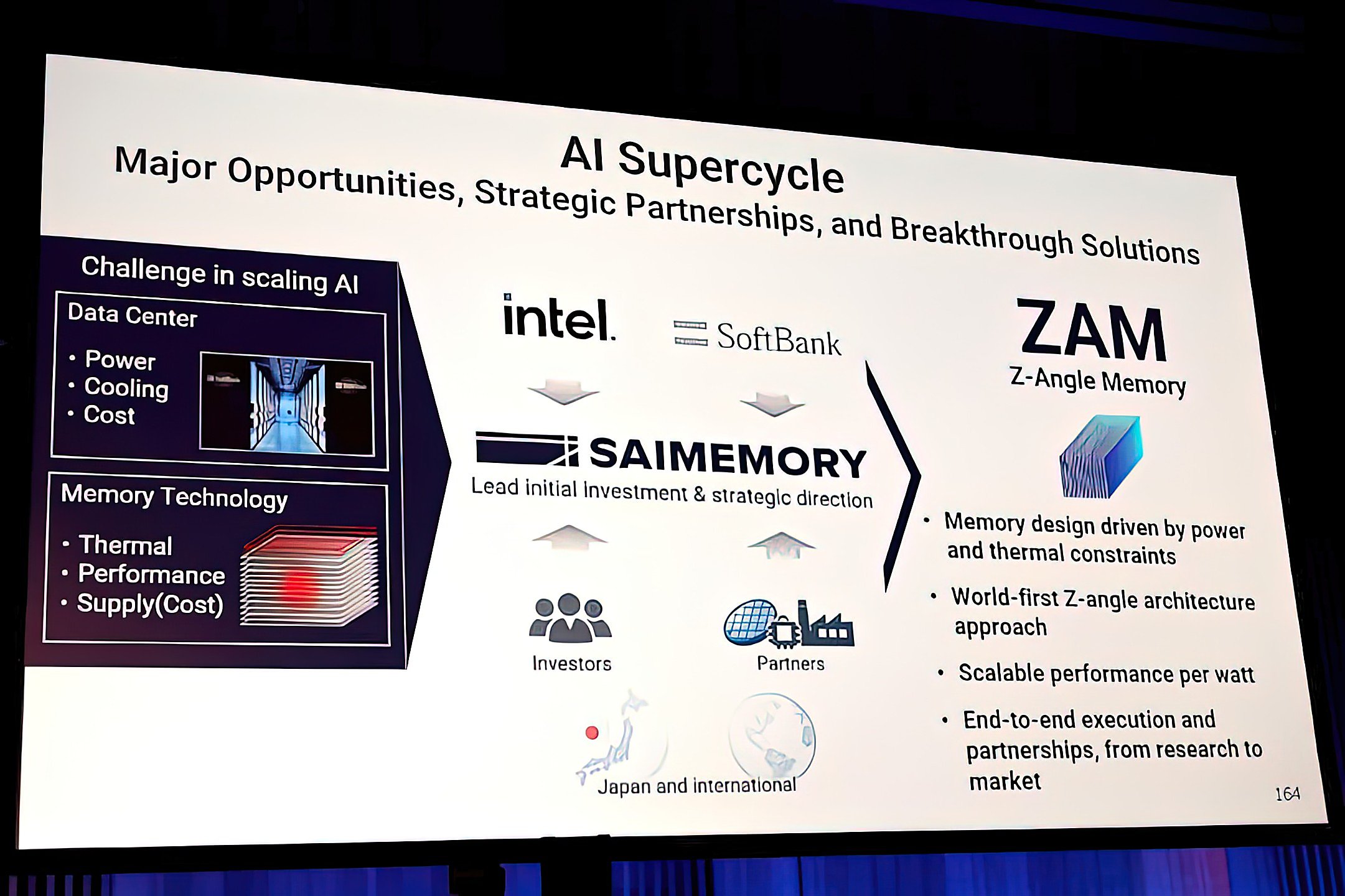
Intel ZAM memory vừa xuất hiện như một hướng đi mới cho bài toán bộ nhớ của chip AI, nơi HBM đang gần như nắm thế độc quyền nhưng cũng ngày càng lộ rõ giới hạn về nhiệt, điện năng và chi phí đóng gói. Thông tin Intel công bố cho thấy kiến trúc này nhắm tới băng thông gấp đôi HBM4, đồng thời tăng dung lượng trên mỗi gói nhớ mà không đẩy nhiệt lên quá cao. Với giới làm hạ tầng AI, đây là chi tiết đáng chú ý vì bộ nhớ đang là nút thắt không kém GPU trong các cụm tăng tốc hiện đại. Điều quan trọng hơn là ZAM không chỉ nói về tốc độ, mà còn là cách sắp xếp lại toàn bộ bài toán truyền dữ liệu trong máy chủ AI. Nếu Intel ZAM đi được tới thương mại hóa, đây có thể là một trong những thay đổi đáng kể nhất của mảng bộ nhớ cho chip tăng tốc.
Intel ZAM memory khác HBM4 ở đâu?
Theo bài giới thiệu của Wccftech, Intel sẽ trình bày thêm về Z-Angle Memory tại VLSI Symposium 2026 cùng SAIMEMORY, công ty do SoftBank hậu thuẫn. Điểm đáng chú ý nhất là mục tiêu đạt băng thông gấp đôi HBM4, thậm chí chạm vùng hiệu năng thường được nhắc tới cho HBM4E, nhưng bằng một cấu trúc được tối ưu riêng cho mật độ cao và điện năng thấp. Nói cách khác, Intel ZAM đang được vẽ ra như một lối đi mới thay vì chỉ là bản nâng cấp nhỏ của HBM4.

Thiết kế mà Intel mô tả gồm 9 lớp xếp chồng, trong đó có 8 lớp DRAM và một lớp logic điều khiển chung. Mỗi lớp DRAM được ngăn bởi nền silicon dày khoảng 3 micromet, đi cùng ba tầng TSV với khoảng 13.700 kết nối xuyên silicon mỗi tầng. Cấu hình thử nghiệm này được nói tới ở mức 1,125 GB mỗi lớp, tương đương khoảng 10 GB cho một stack và 30 GB cho toàn bộ gói nhớ, trong khi băng thông đạt 5,3 TB/giây cho mỗi stack với mật độ khoảng 0,25 Tb/giây/mm2.
Nếu nhìn theo hướng thị trường, ZAM đang đi cùng mạch suy nghĩ với NEO 3D X-DRAM: các hãng đều muốn tìm cách vượt qua giới hạn đóng gói của HBM thay vì chỉ tăng số lớp xếp chồng. Khác biệt của Intel nằm ở kiến trúc thẳng đứng, nơi dữ liệu và nhiệt không phải chen qua quá nhiều lớp dây dẫn như HBM truyền thống, từ đó mở ra dư địa tốt hơn cho tiêu thụ điện và tản nhiệt.
Vì sao ZAM có thể làm thị trường AI accelerator phải chú ý?
HBM vẫn là lựa chọn gần như bắt buộc cho GPU AI và accelerator cao cấp, nhưng đổi lại là bài toán chi phí, nhiệt và nguồn cung rất khó chịu với cả nhà sản xuất lẫn khách hàng triển khai máy chủ. Trong bối cảnh đó, một chuẩn nhớ hứa hẹn nhiều băng thông hơn, dung lượng cao hơn và ít bị dồn nhiệt hơn sẽ tác động trực tiếp tới cách thiết kế cụm AI server và bo tăng tốc trong vài năm tới. Đây cũng là lý do những bài toán packaging như Intel 18A-P hay công nghệ bộ nhớ mới đang được theo dõi sát không kém bản thân GPU.
| Hạng mục | Intel ZAM memory | Ý nghĩa thực tế |
|---|---|---|
| Băng thông mục tiêu | Gấp đôi HBM4 | Giảm nghẽn dữ liệu cho mô hình AI lớn và workload suy luận dày đặc |
| Dung lượng mỗi gói | Khoảng 30 GB trong cấu hình được mô tả | Cho phép nhồi nhiều dữ liệu hơn gần chip xử lý |
| Mật độ băng thông | 0,25 Tb/giây/mm2 | Tăng hiệu quả truyền dữ liệu trên cùng diện tích đóng gói |
| Nhiệt và điện năng | Nhắm tới mức thấp hơn HBM | Giúp hệ thống AI dễ kiểm soát nhiệt và công suất hơn |
| Mốc thời gian | Khoảng 2028-2030 | Chưa phải giải pháp thương mại ngay lập tức |
Chưa dừng lại ở đó, Intel và SAIMEMORY còn nhấn vào cách ghép 3.5D giữa stack bộ nhớ, đường cấp nguồn, silicon photonics và I/O truyền thống trên cùng một đế. Nếu làm được ở quy mô thương mại, ZAM không chỉ cạnh tranh với HBM ở từng con số thông số mà còn có thể thay đổi cách các hãng chia diện tích, điện năng và luồng dữ liệu trong hệ thống AI thế hệ mới.
Dù vậy, ZAM hiện vẫn là lời hứa kỹ thuật nhiều hơn là sản phẩm sẵn sàng bán ra. Đây cũng là lý do các hãng sẽ theo dõi rất kỹ xem Intel ZAM có thể chứng minh hiệu quả ngoài phòng lab hay không. Mốc 2028-2030 cho thấy Intel còn phải chứng minh từ trình diễn thực tế, độ ổn định sản xuất cho tới chi phí triển khai trước khi thuyết phục được các hãng GPU và hyperscaler rời quỹ đạo HBM. Nói ngắn gọn, Intel ZAM memory chưa lật đổ HBM4 hôm nay, nhưng nó đã gửi tín hiệu rằng cuộc đua bộ nhớ cho chip AI sẽ không dừng ở việc xếp thêm lớp DRAM.
2 bình luận về “Intel ZAM thách thức HBM4: bộ nhớ mới cho chip AI có gì đáng chú ý?”