
PCIe 7.0 được tạo ra để đẩy băng thông kết nối giữa CPU, GPU, SSD và chip tăng tốc lên mức rất cao, nhưng điều đó không đồng nghĩa mọi cụm AI sẽ tự động hết nghẽn dữ liệu. Khi nhiều GPU, nhiều ổ NVMe và nhiều tầng bộ nhớ cùng dùng chung hạ tầng, vấn đề lớn nhất lại là cách luồng dữ liệu tranh nhau đi qua hệ thống. Với các trung tâm dữ liệu AI, chỉ cần dữ liệu đến chậm ở một nhịp cũng đủ làm cả cụm phần cứng đắt tiền bị phí thời gian chờ. Rambus đang nhắm đúng vào điểm này với một switch IP mới cho PCIe 7.0, tập trung vào việc dùng đường truyền hiệu quả hơn thay vì chỉ cộng thêm lane.
Vì sao PCIe 7.0 vẫn có thể nghẽn khi GPU AI ngày càng đói dữ liệu
Trong thông báo chính thức về công nghệ Time Division Multiplexing, Rambus nói thẳng rằng cụm AI hiện đại phải đẩy khối dữ liệu rất lớn giữa CPU, GPU, chip tăng tốc và SSD NVMe. Vì vậy, ngay cả khi PCIe 7.0 có băng thông rất cao, liên kết này vẫn có thể bị dùng kém hiệu quả nếu nhiều tác vụ cùng dồn vào một lúc mà không có cơ chế điều phối tốt.
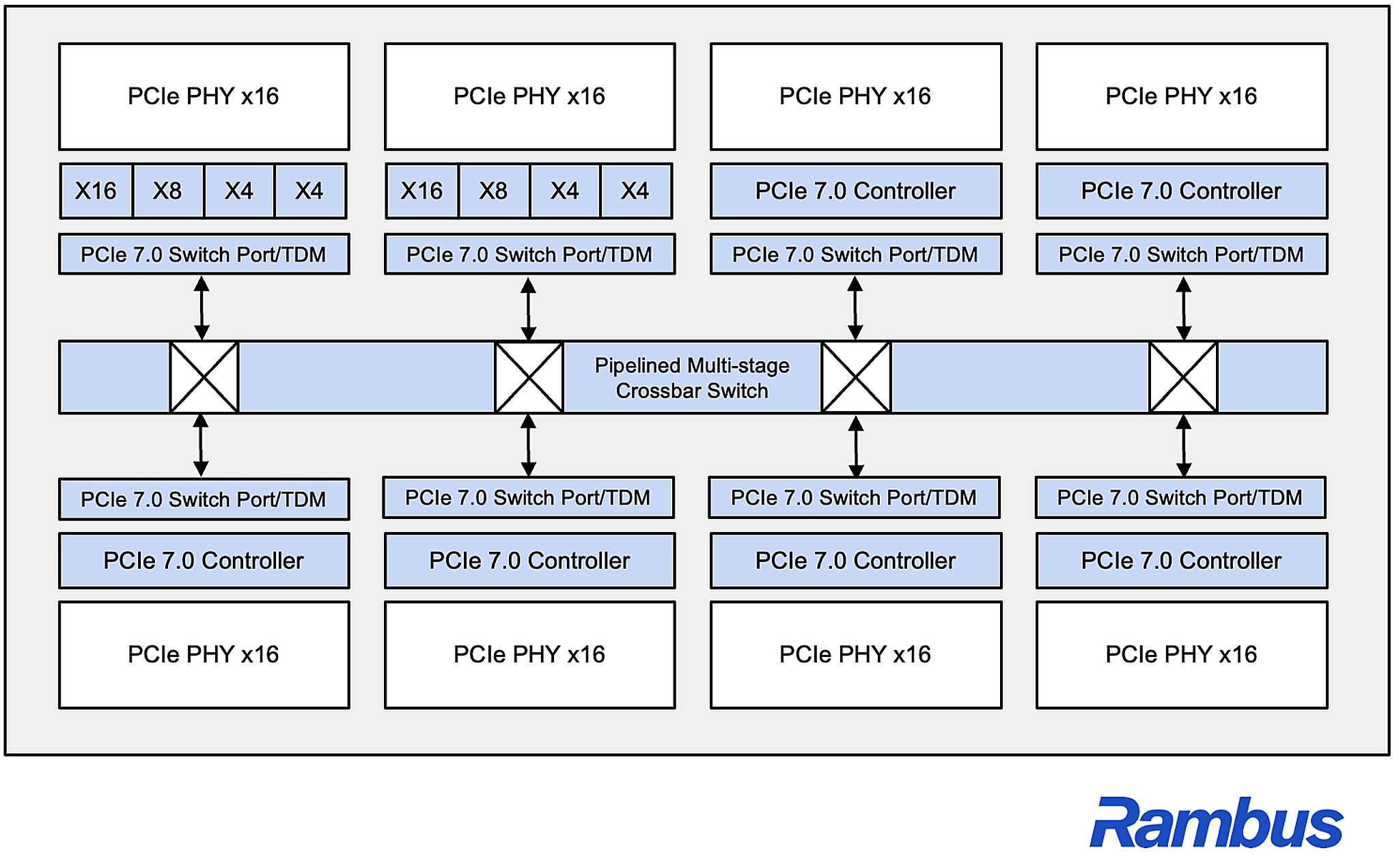
Điểm nghẽn của PCIe 7.0 nằm ở chỗ các hệ thống AI mới không còn là một khối phần cứng cố định. GPU, bộ nhớ và lưu trữ đang được tách rời rồi ghép linh hoạt theo từng tác vụ huấn luyện hoặc suy luận. Càng nhiều tài nguyên dùng chung, PCIe 7.0 càng phải giữ độ trễ thấp và phân phối dữ liệu đều hơn, nếu không GPU rất dễ rơi vào cảnh chờ dữ liệu thay vì xử lý liên tục.
Xu hướng này đi cùng làn sóng tăng băng thông bộ nhớ tại chỗ, nơi các hãng cố rút ngắn thời gian cấp dữ liệu cho chip AI. Bài viết về bộ nhớ HBM4 cho thấy chỉ tăng sức mạnh xử lý là chưa đủ nếu dữ liệu không tới kịp.
Rambus đang xử lý nút thắt đó bằng Time Division Multiplexing như thế nào
Giải pháp Rambus đưa ra cho PCIe 7.0 là thêm Time Division Multiplexing, tức chia thời gian truyền theo lịch để nhiều luồng dữ liệu cùng đi qua liên kết chung theo thứ tự hợp lý hơn. Thay vì để lưu lượng tranh chấp tự do rồi mới xử lý tắc nghẽn, switch có thể ghép và sắp xếp traffic trước, nhờ đó tăng mức sử dụng PCIe 7.0 mà vẫn giữ độ trễ ổn định hơn cho các tác vụ nhạy cảm thời gian.
| Hạng mục | Rambus đưa ra gì | Tác động thực tế |
| Điểm nghẽn | Nhiều GPU, CPU, SSD cùng tranh băng thông PCIe 7.0 | GPU có thể phải chờ dữ liệu dù link rất nhanh |
| Cơ chế mới | Time Division Multiplexing để lập lịch và ghép nhiều luồng trên link chung | Tăng hiệu quả sử dụng đường truyền, giảm lãng phí băng thông |
| Cấu hình switch | Tối đa 2 upstream port, 31 downstream port, 128 lane, hỗ trợ tới 128 GT/s mỗi lane | Dễ xây fabric lớn hơn cho máy chủ AI và ASIC trung tâm dữ liệu |
| Lợi ích hệ thống | Tương thích ngược PCIe 6.3 và 5.0, hỗ trợ peer-to-peer | Giảm độ phức tạp khi scale cả cụm thay vì chỉ tăng phần cứng cục bộ |
Trang sản phẩm của Rambus cho biết switch IP PCIe 7.0 này hỗ trợ tối đa 128 lane, tối đa 2 cổng upstream và 31 cổng downstream, đồng thời tương thích ngược với PCIe 6.3 và PCIe 5.0. Đây là lớp kết nối dành cho ASIC, FPGA và máy chủ AI cần xây fabric lớn, nhiều điểm kết nối và luồng peer-to-peer giữa các thiết bị tăng tốc.
Điểm đáng tiền nhất là Rambus đang bán PCIe 7.0 như cách giảm số lượng PHY, độ trễ, điện năng và chi phí khi hệ thống phình to. Điều này rất đáng theo dõi khi các thiết kế rack AI ngày càng dày đặc; bài viết về rack AI NVIDIA cho thấy chỉ riêng hạ tầng điện và kết nối cũng đã đủ đẩy tổng chi phí lên mạnh.
Nếu phần điều phối lưu lượng làm đúng như Rambus hứa, PCIe 7.0 sẽ không chỉ nhanh hơn trên thông số mà còn hữu ích hơn trong thực tế triển khai. Với cụm GPU AI và máy chủ suy luận, đó mới là giá trị quan trọng nhất: giữ cho phần cứng đắt tiền luôn có dữ liệu để chạy thay vì nằm chờ ở giữa đường.
2 bình luận về “PCIe 7.0 có thể thành nút thắt GPU AI, Rambus muốn gỡ ra sao?”